")
Содержание
Расчет релевантности статей и выдачи с помощью нейронных сетей. Скрипт на Python позволяет рассчитывать текстовую релевантность с помощью LaBSE (Language-agnostic BERT Sentence Embedding) с помощью метода косинусной близости. Это самый идеальный метод расчета, так как чистый BERT для расчета использовать не рекомендуют даже его разработчики.
Установка скрипта
1) Если вы никогда не использовали python, то тут 4 минутное видео с установки Python и IDE Pycharm. Это все что необходимо.
2) Скачиваем код из https://github.com/Devvver/vector_text_bert
3) Запускаем. В процессе с интернета скачается сама LaBSE (размер около 2 гигабайт). По этой причине первый запуск может быть долгим, дальше все закешируется и будет работать шустро.
Скрипт работает на CPU и на моем ноутбуке выполняет в среднем около 2 запросов в секунду. Если у вас мощная видеокарта можно переделать проект под GPU.
Расчет текстовой релевантности для запроса и статьи
Расчет текстовой релевантности для запроса и статьи. Это может быть как ваша статья, так и просто кусок текста от конкурента. С помощью этого метода для каждого абзаца будет рассчитана своя релевантность. Удобно также юзать для PBN — рассчитывать релевантность абзаца с которого будете ссылаться на другой сайт (бустит жестко позиции), генерировать максимально релевантное околоссылочное, title, заголовок.

Пример на скриншоте:

Жмем на Рассчитать и получаем результат:
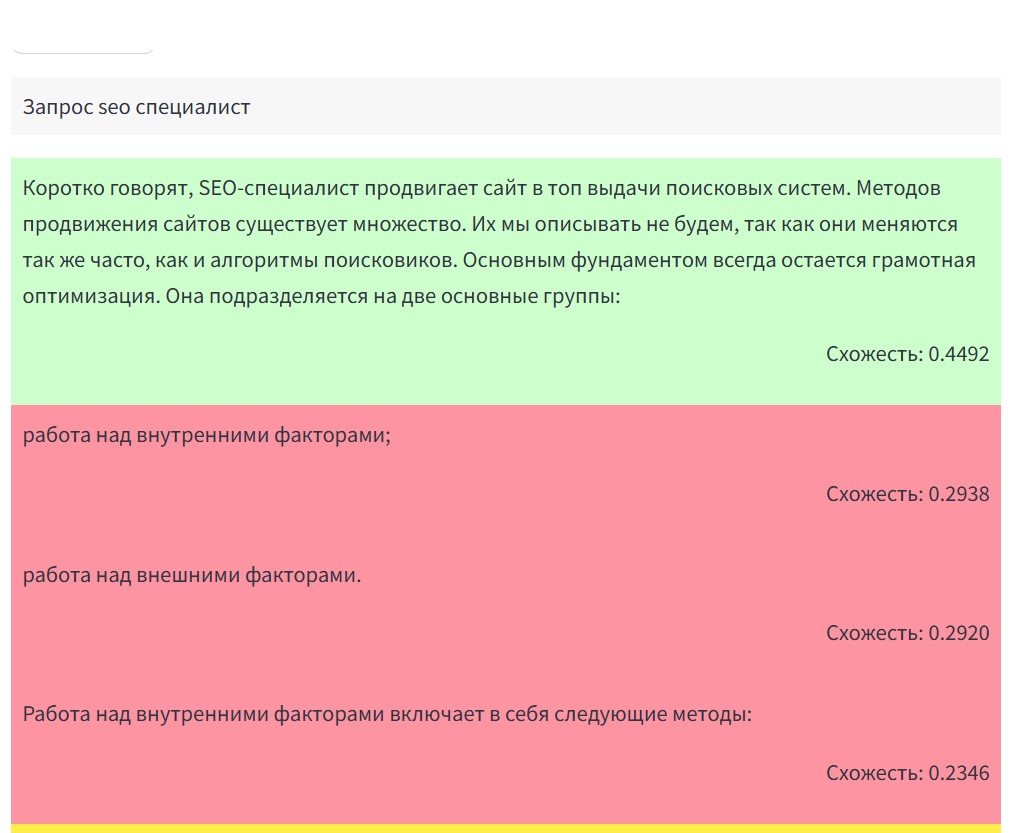

LABSE поддерживает 110 языков, в том числе и русский украинский, американский, подробнее можно почитать о ней здесь, как и увидеть примеры использования. Научные труды по ее работе рассматриваются здесь.
Расчет релевантности для запроса и сайтов
Расчет релевантности для запроса и сайтов (идеально использовать топ 10 выдачи).
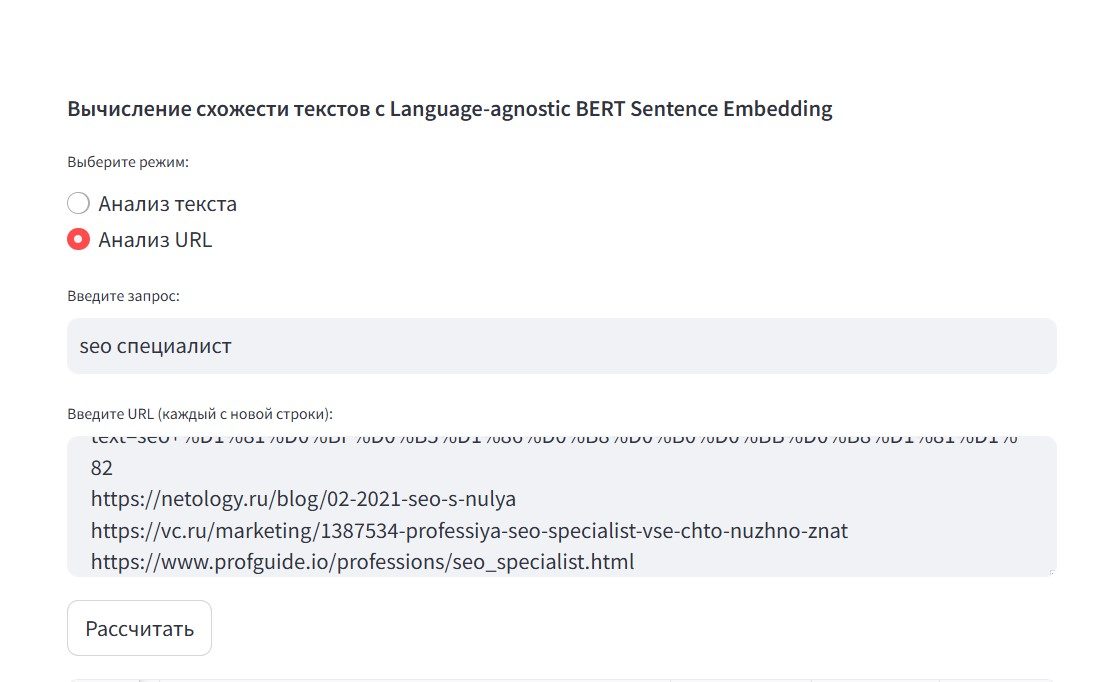
Переключаемся на режим «Анализ URL». Вводим наш запрос, в поле ввода вбиваем список url из топ 10.
Получить топ 10 можно с помощью расширения «Search Results Extractor«. Если вам нужны результаты по конкретных регионам из Гугла или Яндекса используйте бесплатный https://pr-cy.ru/tools/check-keywords/ (требуется регистрация, которая дает 10 запросов в сутки).
Выглядеть должно так:
Скрипт скачает тексты статей, title, h1 с каждого сайта и рассчитает семантическую схожесть векторов с помощью косинусной близости. Вы получите результат:
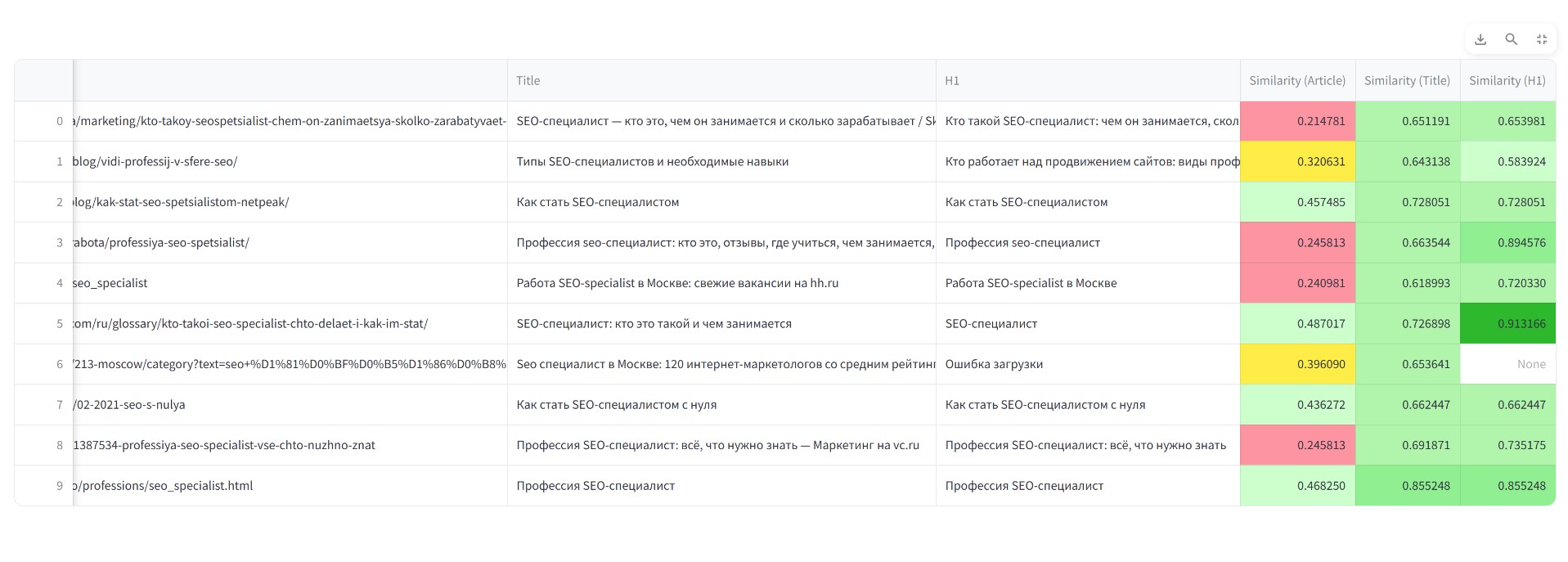
Вы увидите реальное соответствие запросу сайтов по их текстовому ранжированию. Но почему сайты не идут в порядке качества? Ответ прост, текстовое ранжирование занимает в современных поисковых системах не более 30-40 % от остальных факторов. Тем не менее таким методом можно сравнить свою статью с другими, чтобы понимать, а максимально вы постарались в качестве текста по сравнению с конкурентами.
Также вы можете обратить внимание, что у векторного BERT ранжирования есть один неприятный недостаток — чем больше текст, тем ниже значение. Именно по этой причине Bert используется вместе с другими алгоритмами, как то TF-IDF или Word2Vec.
Чтобы подытожить хочется объяснить почему все таки использовалась LaBSE, а не чистый BERT. В нем есть большой недостаток, он больше подходит для классификации текста, а не ранжирования. Подробно разжевано это в статье на английском языке и если вы хотите заниматься ранжированием с помощью BERT рекомендую с ней ознакомиться.
Если вы интересуетесь скриптами под SEO на python — подписывайтесь на новый телеграмм канал.



3 комментария
На 7 не работает vector.py
Не понял. 7 это что, 7 Windows? Точно не заработает.
Да на винде 7, но я уже исправил для 7 на основе Вашего скрипта. Все работает. Супер скрипт